پردازش زبان طبیعی
پردازش زبان طبیعی از برنامه هایی پشتیبانی می کند که می توانند کاربران را ببینند، بشنوند، با آنها صحبت کنند و درک کنند. Microsoft Azure با استفاده از خدمات تجزیه و تحلیل متن، ترجمه و درک زبان، ساخت برنامه هایی را که از زبان طبیعی پشتیبانی می کنند آسان می کند.
برای اینکه سیستمهای رایانهای موضوع یک متن را به روشی مشابه تفسیر کنند، از پردازش زبان طبیعی (NLP) استفاده میکنند، حوزهای در هوش مصنوعی که با درک زبان نوشتاری یا گفتاری و پاسخگویی مشابه سروکار دارد. تجزیه و تحلیل متن فرآیندهای NLP را توصیف می کند که اطلاعات را از متن بدون ساختار استخراج می کند.
پردازش زبان طبیعی ممکن است برای ایجاد موارد زیر استفاده شود:
یک تحلیلگر فید رسانه های اجتماعی که احساسات را برای یک کمپین بازاریابی محصول تشخیص می دهد.
یک برنامه جستجوی اسناد که اسناد را در یک کاتالوگ خلاصه می کند.
اپلیکیشنی که برندها و نام شرکت ها را از متن استخراج می کند.
Azure AI Language یک سرویس مبتنی بر ابر است که شامل ویژگی هایی برای درک و تجزیه و تحلیل متن است. زبان هوش مصنوعی Azure شامل ویژگی های مختلفی است که از تجزیه و تحلیل احساسات، شناسایی عبارات کلیدی، خلاصه سازی متن و درک زبان محاوره ای پشتیبانی می کند.
تجزیه و تحلیل متن را درک کنید
قبل از بررسی قابلیتهای تجزیه و تحلیل متن سرویس Azure AI Language، اجازه دهید برخی از اصول کلی و تکنیکهای رایج مورد استفاده برای انجام تحلیل متن و سایر وظایف پردازش زبان طبیعی (NLP) را بررسی کنیم.
برخی از اولین تکنیک های مورد استفاده برای تجزیه و تحلیل متن با رایانه شامل تجزیه و تحلیل آماری بدنه ای از متن (یک پیکره) برای استنتاج نوعی معنا است. به زبان ساده، اگر بتوانید متداول ترین کلماتی که در یک سند مورد استفاده قرار می گیرد را تعیین کنید، اغلب می توانید ایده خوبی از موضوع سند به دست آورید.
توکن سازی
اولین گام در تجزیه و تحلیل یک پیکره، تجزیه آن به توکن است. برای سادگی، میتوانید هر کلمه متمایز در متن آموزشی را به عنوان یک نشانه در نظر بگیرید، اگرچه در واقعیت، نشانهها میتوانند برای کلمات جزئی یا ترکیبی از کلمات و علائم نگارشی تولید شوند.
به عنوان مثال، این عبارت را از یک سخنرانی معروف رئیس جمهور ایالات متحده در نظر بگیرید: “we choose to go to the moon“. عبارت را می توان با شناسه های عددی به نشانه های زیر تقسیم کرد:
- we
- choose
- to
- go
- the
- moon
توجه داشته باشید که “to” (ژتون شماره ۳) دو بار در مجموعه استفاده می شود. عبارت “we choose to go to the moon” را می توان با نشانه ها نشان داد [۱،۲،۳،۴،۳،۵،۶].
ما از یک مثال ساده استفاده کرده ایم که در آن نشانه ها برای هر کلمه متمایز در متن مشخص می شوند. با این حال، بسته به نوع خاصی از مشکل NLP که میخواهید حل کنید، مفاهیم زیر را در نظر بگیرید که ممکن است برای توکنسازی اعمال شود:
Text normalization: قبل از ایجاد نشانه، می توانید متن را با حذف علائم نگارشی و تغییر همه کلمات به حروف کوچک عادی سازی کنید. برای تحلیلی که صرفاً بر بسامد کلمات متکی است، این رویکرد عملکرد کلی را بهبود می بخشد. با این حال، ممکن است برخی از معنای معنایی از بین برود – به عنوان مثال، جمله “آقای بنکس در بسیاری از بانک ها کار کرده است” را در نظر بگیرید. ممکن است بخواهید تحلیل شما بین شخص آقای بنکس و بانک هایی که در آنها کار کرده است، تفاوت قائل شود. همچنین ممکن است بخواهید “بانک ها” را در نظر بگیرید. به عنوان یک نشانه جداگانه برای “بانک ها” زیرا گنجاندن یک نقطه اطلاعاتی را ارائه می دهد که کلمه در پایان یک جمله آمده است.
Stop word removal: کلمات توقف کلماتی هستند که باید از تحلیل حذف شوند. برای مثال، «the»، «a» یا «it» خواندن متن را برای مردم آسانتر میکند اما معنای کمی به آن اضافه میکند. با حذف این کلمات، یک راه حل تحلیل متن ممکن است بهتر بتواند کلمات مهم را شناسایی کند.
n-gram: عباراتی چند جمله ای مانند “من دارم” یا “او راه می رفت” هستند. یک عبارت تک کلمه ای یونیگرام، یک عبارت دو کلمه ای یک bi-grams، یک عبارت سه کلمه ای tri-gram و غیره است. با در نظر گرفتن کلمات به عنوان گروه، یک مدل یادگیری ماشینی می تواند درک بهتری از متن داشته باشد.
Stemming: تکنیکی است که در آن از الگوریتمهایی برای تجمیع کلمات قبل از شمارش آنها استفاده میشود، به طوری که کلمات با ریشه یکسان مانند “قدرت”، “قدرتمند” و “قدرتمند” به عنوان یک نشانه تفسیر میشوند.
تحلیل فرکانس
پس از توکن کردن کلمات، میتوانید تجزیه و تحلیل انجام دهید تا تعداد دفعات هر نشانه را بشمارید. متداول ترین کلمات (به غیر از کلمات توقف مانند “a”، “the” و غیره) اغلب می توانند سرنخی از موضوع اصلی یک مجموعه متن ارائه دهند. به عنوان مثال، رایج ترین کلمات در کل متن سخنرانی “برو به ماه” که قبلا در نظر گرفتیم شامل “new“, “go“, “space“, و “moon” است. اگر بخواهیم متن را به صورت bi-grams (جفت کلمه) نشانه گذاری کنیم، رایج ترین bi-grams در گفتار “the moon” است. از این اطلاعات، به راحتی می توان حدس زد که متن در درجه اول مربوط به سفر فضایی و رفتن به ماه است.
نکته
تجزیه و تحلیل فرکانس ساده که در آن شما به سادگی تعداد دفعات هر توکن را می شمارید، می تواند یک روش موثر برای تجزیه و تحلیل یک سند واحد باشد، اما زمانی که نیاز به تمایز بین چندین سند در یک مجموعه دارید، به روشی نیاز دارید تا مشخص کنید کدام نشانه ها بیشتر هستند. مربوط به هر سند فراوانی اصطلاح – بسامد معکوس سند (TF-IDF) یک تکنیک رایج است که در آن امتیاز بر اساس تعداد دفعات ظاهر شدن یک کلمه یا عبارت در یک سند در مقایسه با فراوانی عمومی تر آن در کل مجموعه اسناد محاسبه می شود. با استفاده از این تکنیک، درجه بالایی از ارتباط برای کلماتی که اغلب در یک سند خاص ظاهر می شوند، اما در طیف گسترده ای از اسناد دیگر به ندرت در نظر گرفته می شود.
یادگیری ماشینی برای طبقه بندی متن
یکی دیگر از تکنیک های مفید تجزیه و تحلیل متن، استفاده از یک الگوریتم طبقه بندی، مانند logistic regression، برای آموزش یک مدل یادگیری ماشینی است که متن را بر اساس مجموعه ای شناخته شده از طبقه بندی ها طبقه بندی می کند. یکی از کاربردهای رایج این تکنیک، آموزش مدلی است که متن را به عنوان مثبت یا منفی طبقهبندی میکند تا تحلیل احساسات یا نظر کاوی انجام شود.
به عنوان مثال، نظرات رستوران زیر را در نظر بگیرید که قبلاً به عنوان ۰ (منفی) یا ۱ (مثبت) برچسب گذاری شده اند:
غذا و خدمات هر دو عالی بود: ۱
یک تجربه واقعا وحشتناک: ۰
اممم! غذای خوشمزه و حال و هوای سرگرم کننده: ۱
خدمات آهسته و غذای نامرغوب: ۰
با مرورهای برچسبدار کافی، میتوانید یک مدل طبقهبندی را با استفاده از متن نشانهگذاری شده به عنوان ویژگی و احساسات (۰ یا ۱) یک برچسب آموزش دهید. این مدل یک رابطه بین نشانهها و احساسات را در بر میگیرد – برای مثال، نظرات با نشانههایی برای کلماتی مانند “عالی”، “خوشمزه” یا “سرگرم کننده” به احتمال زیاد احساس ۱ (مثبت) را برمیگردانند، در حالی که نظرات با کلماتی مانند “وحشتناک”، “کند” و “غیر استاندارد” احتمال بازگشت ۰ (منفی) بیشتر است.
مدل های زبان معنایی
با پیشرفت NLP، توانایی آموزش مدل هایی که رابطه معنایی بین توکن ها را در بر می گیرند، منجر به ظهور مدل های زبان قدرتمند شده است. در قلب این مدلها، رمزگذاری نشانههای زبان بهعنوان بردار (آرایههای چند ارزشی از اعداد) است که به عنوان جاسازیها شناخته میشوند.
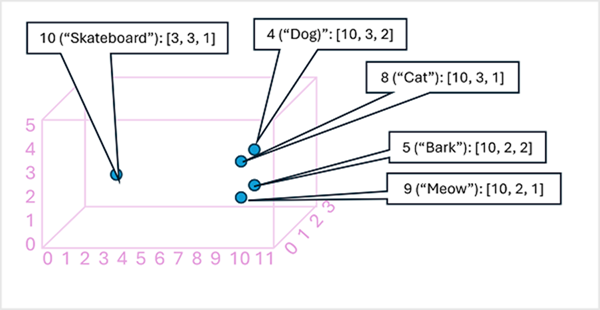
این می تواند مفید باشد که عناصر را در یک بردار جاسازی نشانه به عنوان مختصاتی در فضای چند بعدی در نظر بگیریم، به طوری که هر نشانه یک “مکان” خاص را اشغال کند. هر چه نشانهها در یک بعد خاص به یکدیگر نزدیکتر باشند، از نظر معنایی مرتبطتر هستند. به عبارت دیگر، کلمات مرتبط نزدیکتر به هم گروه بندی می شوند. به عنوان یک مثال ساده، فرض کنید جاسازیهای توکنهای ما شامل بردارهایی با سه عنصر است، برای مثال:
۴ (“dog”): [10.3.2]
5 (“bark”): [10،۲،۲]
۸ (“cat”): [10،۳،۱]
۹ (“meow”): [10،۲،۱]
۱۰ (“skateboard”): [3،۳،۱]
میتوانیم مکان توکنها را بر اساس این بردارها در فضای سهبعدی ترسیم کنیم، مانند:
نموداری از نشانه ها که بر روی یک فضای سه بعدی رسم شده است.
مکان توکن ها در فضا حاوی اطلاعاتی در مورد ارتباط نزدیک توکن ها با یکدیگر است. به عنوان مثال، نشانه “dog” به “cat” و همچنین به “bark” نزدیک است. نشانه های “cat” و “bark” نزدیک به “meow” هستند. نشانه “skateboard” از سایر نشانه ها دورتر است.
مدل های زبانی که ما در صنعت استفاده می کنیم بر اساس این اصول هستند اما پیچیدگی بیشتری دارند. برای مثال، بردارهای مورد استفاده عموماً ابعاد بسیار بیشتری دارند. همچنین راههای متعددی وجود دارد که میتوانید جاسازیهای مناسب را برای مجموعهای از نشانهها محاسبه کنید. روشهای مختلف منجر به پیشبینیهای متفاوتی از مدلهای پردازش زبان طبیعی میشوند.
یک نمای کلی از اکثر راه حل های مدرن پردازش زبان طبیعی در نمودار زیر نشان داده شده است. مجموعه بزرگی از متن خام نشانه گذاری شده و برای آموزش مدل های زبان استفاده می شود، که می تواند انواع مختلفی از وظایف پردازش زبان طبیعی را پشتیبانی کند.
نموداری از فرآیند توکن کردن متن و آموزش یک مدل زبان که از وظایف پردازش زبان طبیعی پشتیبانی می کند.
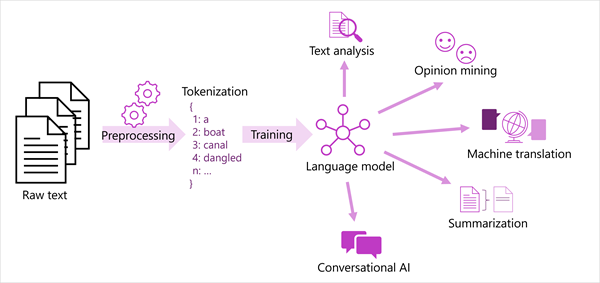
وظایف رایج NLP که توسط مدل های زبان پشتیبانی می شوند عبارتند از:
تجزیه و تحلیل متن، مانند استخراج اصطلاحات کلیدی یا شناسایی موجودیت های نامگذاری شده در متن.
تجزیه و تحلیل احساسات و نظر کاوی برای دسته بندی متن به عنوان مثبت یا منفی.
ترجمه ماشینی، که در آن متن به طور خودکار از یک زبان به زبان دیگر ترجمه می شود.
خلاصه سازی که در آن نکات اصلی حجم وسیعی از متن خلاصه می شود.
راهحلهای هوش مصنوعی مکالمهای مانند رباتها یا دستیارهای دیجیتال که در آن مدل زبان میتواند ورودی زبان طبیعی را تفسیر کند و پاسخ مناسبی را ارائه دهد.
برای خواندن ادامه این آموزش از منبع رسمی مایکروسافت لرن کلیک کنید
Overview
0 مورد نقد و بررسی